Data De-identification
Disclosing sensitive information without proper safeguards can lead to significant harm and jeopardize not only the well-being of participants but also the integrity and trustworthiness of the research process.
The richness of the data obtained through interviews presents additional ethical and analytical challenges, particularly regarding the need for more nuanced and intricate analysis, concerning the protection of participant identity, and the mitigation of the risk of re-identification.
Qualitative data can be more difficult to de-identify compared to quantitative data due to its typically unstructured nature. Another challenge is that qualitative data includes unique personal narratives and contextual details that can inadvertently reveal identities, requiring careful and nuanced de-identification strategies to protect participants’ privacy effectively. The process of de-identification or anonymization can also alter or diminish data value, especially when the significance lies in capturing personal experiences or narratives. Researchers should consider using de-identification alongside other methods, such as limiting access to the data or obtaining explicit consent from participants to share some or all of their personal information. Because extensive de-identification might sometimes obscure important details needed for deep analysis, striking a balance between removing identifiers and preserving the essential context of the qualitative data is key.
In a nutshell, data de-identification entails the process of removing direct and indirect identifiers from a dataset, while maintaining enough information to preserve its value and usability to future research. In this episode, we cover common strategies for de-identifying interview data and recommendations for handling sensitive information.
Direct vs Indirect Identifiers
A person’s identity can be disclosed from direct identifiers, which are unique to an individual, or indirect identifiers which, when linked with other available information, could identify someone.
Direct identifiers are pieces of information that can immediately identify an individual on their own, such as a social security number, full name, email address, home address, or phone number. In contrast, indirect identifiers are data points that do not uniquely identify someone by themselves but can do so when combined with other information. Examples of indirect identifiers include job title, gender, and ethnicity. The risk associated with indirect identifiers can vary depending on the context and the availability of additional data. Therefore, it is crucial to understand which data points are relevant within the context of the study and to consider both direct and indirect identifiers to effectively protect privacy and minimize the risk of identification.
Source: UCSB Library Data Literacy Series (perma.cc/LM2L-K8DN).
Initially, researchers might change names and disguise locations, but effectively managing identifying details in qualitative data requires a nuanced approach. Anonymity and privacy exist on a spectrum, so researchers must balance the risk of identification with the needs of their research.
When data isn’t fully anonymized, including cases of potential indirect identification, obtaining explicit consent is essential before public release. This consent should be secured either at the time of data collection or prior to publication.
One significant challenge arises with indirect identification, particularly in small groups where participants know each other. This issue can be exacerbated by existing power dynamics, such as those between a team and its leader. Therefore, researchers must transparently communicate the risks of identity disclosure to participants and respect their wishes.
To mitigate these risks, techniques such as using multiple pseudonyms, rephrasing quotes, and breaking known links can be effective. These methods help protect participant identities while allowing for restricted sharing of the dataset.
However, there may be situations where these strategies are not feasible. In such cases, researchers need to carefully consider how to obtain consent for disclosing an individual’s identity without inadvertently revealing the identities of others. Ultimately, the outcomes of these processes should be documented in the data management plan and ethics application, ensuring that all considerations are addressed.
Data De-identification Essentials
The existing literature provides limited guidance on de-identifying qualitative data, with most researchers relying on ad hoc strategies. Perhaps the most robust and up-to-date methodological framework for handling sensitive narrative data is found in Campbell and co-authors (2023) multiphased process inspired by common qualitative coding techniques.
In the first phase, the process involves consultations with a range of stakeholders and subject-matter experts to identify risks related to re-identifiability and concerns about data sharing. The second phase outlines an iterative approach to identifying potentially identifiable information and developing tailored remediation strategies through group review and consensus. The final phase includes multiple methods for evaluating the effectiveness of the de-identification efforts, ensuring that the remediated transcripts adequately protect participants’ privacy. If your project involves working with vulnerable or protected groups, or handling sensitive data, we strongly recommend reviewing and applying this framework to your research.
![]()
These three phases can be broken into tasks, actions and examples:
| Phase goal | Tasks | Actions | Examples |
|---|---|---|---|
Phase 1: Develop a process to distinguish potentially identifiable data |
Create a coding framework | Consult with stakeholders and look for strategies followed by similar projects | Regulatory guidance (HIPPAA, IRB, relevant professional and research associations) |
| Subject-matter experts familiar with the population studied | |||
| Publicly available records that may contain same/similar information as the research-interview transcripts | |||
| Draft a codebook | Scan for named entities (e.g., names, places, dates) | ||
| List potential identifiable topics | |||
| Guidance for evaluating ambiguous information others or public records might have and that combined could jeopardize privacy and confidentiality | |||
Phase 2: Remediate potentially identifiable data |
Establish a coding team* | Hire and train coders | Include coders with varying levels of familiarity with the data |
| Review transcripts and propose re mediation plans | Highlight each data point and create an audit trail containing proposed edits | Draft blurred text | |
| Bracket redacted text | |||
| Review proposed remediation plans and discuss as a team | |||
| Implement remediation plans | Edit and redact text | Insert blurred text, remove redacted text, and insert summaries in the event of important long redactions | |
| Provide support to coding team if there will be repeated exposure to traumatic content* | Check in with team members regarding their experiences of vicarious trauma | Provide information and support regarding the emotional impact of repeated exposure to traumatic content and offer supportive resources | | |||
Phase 3: Assess the validity of the de-identification analyses |
Select validity standards | Assess credibility (i.e., confidence in the accuracy of the findings) | Use of prolonged engagement, persistent engagement, and member checks to assess accuracy of the findings |
| Assess dependability (i.e., the findings are consistent and could be repeated) | Use of codebooks, memos, and audit trails to document analyses | ||
| Assess transferability (i.e., the findings have applicability in other con texts) | Provide audiences with sufficient detail about the project so they can assess whether conclusions are transferable to other settings | ||
| Assess confirmability (i.e., the findings reflect the participants’ views, not the researchers’ biases) | Consider how researchers’ positionalities affected the processes and findings and when necessary, recenter the participants’ views | |
*Not applicable to small-scale studies. Source: Adapted from: Campbell et al. (2023).
Now, let’s focus on some practical ways to remediate potentially identifiable data in interview transcripts. General recommendations include:
Establish uniform de-identification rules at the start of your project and apply them consistently throughout, especially when working with a team.
Thoroughly review data to pinpoint any details that could lead to individual identification.
Assign a unique identifier to each participant to replace their name.
Replace real names (people, companies) with pseudonyms.
Generalize location details and dates (e.g., North Carolina → [Southeast], 1977 → [1975-1980])
Generalize meaning of detailed variables (e.g., specific professional position → occupation or area of expertise)
Remove or redact sensitive text or entire sections as needed.
Avoid blanking out or replacing items without any indication. The use of brackets indicates that something has been changed, modified, or deleted from its original form.
Maintain a master log of all replacements, aggregations, or removals made and keep it in a secure location separate from the de-identified data files.
In a single excerpt, you can integrate multiple de-identification techniques. The example below illustrates how an excerpt has been de-identified, with the modifications clearly indicated, while still retaining essential information for future analysis.
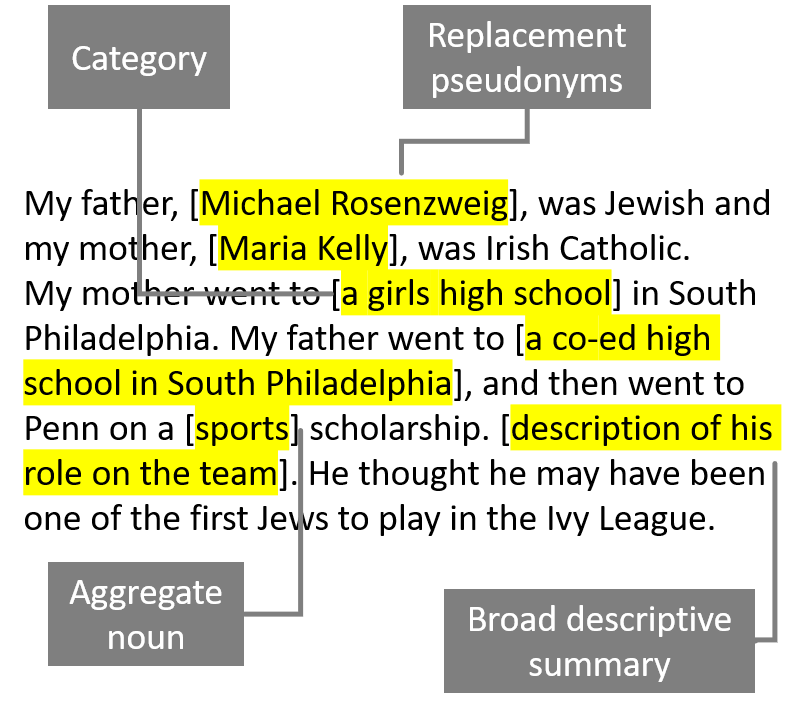
This handout provides a compilation with some helpful tips:
Source: UCSB Library Data Literacy Series (perma.cc/LM2L-K8DN).
Having promised to keep participants’ identities confidential, Sarah has assigned pseudonyms to interviewees. However, she is uncertain how to handle indirect identifiers. We will help her to address these issues confidently.
Adopting best practices for de-identifying responses from your human participants can significantly enhance both the ease and reliability of this process. It’s crucial to incorporate de-identification considerations early in your planning phase as part of your overall data management strategy. Decisions on which data to collect, what to exclude, and how to inform participants about de-identification will profoundly impact how you can use and share the data in the future as we will explore in future episodes.
Automating the De-id Process
You might be wondering how to effectively perform data de-identification for qualitative data. A open source and free tool to support this processes is QualiAnon. Specifically designed for qualitative interview data, QualiAnon was developed by the Qualiservice Research Data Center from University of Bremen, Germany, to support the anonymization of text data. It is particularly useful for anonymizing interview transcripts in the qualitative social sciences, ensuring that data can be safely archived without compromising participant confidentiality.
For information on installation, user manual, and more visit: https://github.com/pangaea-data-publisher/qualianon/releases
Recommended/Cited Sources:
Campbell R, Javorka M, Engleton J, Fishwick K, Gregory K, Goodman-Williams R. Open-Science Guidance for Qualitative Research: An Empirically Validated Approach for De-Identifying Sensitive Narrative Data. Advances in Methods and Practices in Psychological Science. 2023;6(4). doi:10.1177/25152459231205832
Myers CA, Long SE, Polasek FO. Protecting participant privacy while maintaining content and context: Challenges in qualitative data De-identification and sharing. ProcAssoc Inf Sci Technol. 2020;57:e415. https://doi.org/10.1002/pra2.415